






|
Sysadmin/musician/theatre techie. If you use identi.ca I'm jmdh there.
|

Oxford

4 public comments

An immediate classic.
San Francisco

Birds that are 6 to 8 meters in diameter? Maybe he has a T-Rex on his block? https://twitter.com/OffDaMolly/status/690702529898872833?s=09
Silicon Valley, CA
Why is the Earth so far away from "me"?
New Baltimore, MI
I am disappointed in the lack of "Objects formerly known as planets" on the diagram. Where is the pluto love!










Oxford
7 public comments
Gruselig

In 3 years time, Star Wars will be 40 years old. In 5 years time the Phantom Disappointment will be 20 years old.

.
Atlanta, GA

Timeghost
Berlin/Germany


alt-text: 'Hello, Ghostbusters?' 'ooOOoooo people born years after that movie came out are having a second chiiiild right now ooOoooOoo'
Tarrytown, NY









































Oxford
27 public comments
crystal clear
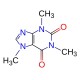
XKCD explains heartbleed
San Jose, California
good simple explanation of heartbleed
Boston, MA
Computer Science 101
Clemson, SC

The best explanation of Heartbleed I've seen.
Belgium
Simple is good.
Sactown, CA

Best explanation, yet.
Wherever

Heartbleed: a simple explanation. It affected a huge number of websites. Be safe and change your passwords!
Great explanation of Heartbleed that is causing internet security issues all over the place.
McKinney, Texas

You know I'm only sharing this because I've never seen a story this shared before. 56 people! 57 now.
I should get back to work.
I should get back to work.
Atlanta, Georgia

If you aren't a techie, this will explain the Heartbleed bug to you super-simply.
Aurora, IL

Perfect explanation of how Heartbleed works.
37.259417,-79.935122
Perfect.
Denver
.
Atlanta, GA
nice
New York, NY
You can’t explain it simpler and more to the point

Ah, now I understand.
East Helena, MT



Debops
What I like the most about being a Developer is building tools to (hopefully) make someone's life better.
I like it when my software gets used, and people thank me for it, because there was a need they had that wasn't met before, and thanks to my software now it is being met.
I am maintaining software for meteorological research that is soon going to be 10 years old, and is still evolving and getting Real Work done.
I like to develop software as if it is going to become a part of human cultural heritage, developing beyond my capacity, eventually surviving me, allowing society to declare that the need, small as it was, is now met, and move on to worry about some other problem.
I feel that if I'm not thinking of my software in that way, then I am not being serious. Then I am not developing something fit for other people to use and rely on.
This involves Development as much as it involves Operations: tracking security updates for all the components that make up a system. Testing. Quality assurance. Scalability. Stability. Hardening. Monitoring. Maintenance requirements. Deployment and upgrade workflows. Security.
I came to learn that the requirements put forward by sysadmins are to be taken seriously, because they are the ones whose phone will ring in the middle of the night when your software breaks.
I am also involved in more than one software project. I am responsible for about a dozen web applications deployed out there in the wild, and possibly another dozen of non-web projects, from terabyte-sized specialised archival tools to little utilities that are essential links in someone's complex toolchain.
I build my software targeting Debian Stable + Backports. At FOSDEM I noticed that some people consider it uncool. I was perplexed.
It provides me with gives me a vast and reasonably recent set of parts to use to build my systems.
It provides me with gives me a single bug tracking system for all of them, and tools to track known issues in the systems I deployed.
It provides me with gives me a stable platform, with a well documented upgrade path to the next version.
It gives me a release rhythm that allows me to enjoy the sweet hum of spinning fans thinking about my next mischief, instead of spending my waking time chasing configuration file changes and API changes deep down in my dependency chain.
It allows me to rely on Debian for security updates, so I don't have to track upstream activity for each one of the building blocks of the systems I deploy.
It allows me not to worry about a lot of obscure domain specific integration issues. Coinstallability of libraries with different ABI versions. Flawless support for different versions of Python, or Lua, or for different versions of C++ compilers.
It has often happened to me to hear someone rant about a frustrating situation, wonder how come it had never happened to me, and realise that someone in Debian, who happens to be more expert than I can possibly be, had thought hard about how to deal with that issue, years before.
I know I cannot be an expert of the entire stack from bare iron all the way up, and I have learnt to stand on the shoulders of giants.
'Devops' makes sense for me in that it hints at this cooperation between developers and operators, having constructive communication, knowing that each side has their own needs, trying their best to meet them all.
It hints at a perfect world where developers and operators finally come to understand and trust each other's judgement.
I don't know that about perfect world, but I, a developer, do like to try to understand and trust the judgement of sysadmins.
I sympathise with my sysadmin friends who feel that devops is turning into a trend of developers thinking they can do without sysadmins. Reinventing package managers. Bundling dependencies. Building "apps" apps instead of components.
I wish that people who deploy a system built on such premises, have it become so successful that they end up being paid to maintain them for their whole career. That is certainly what I wish and strive for, for me and my own projects.
In my experience, a sustainable and maintainable system won't come out of the startup mindset of building something quick&dirty, then sell it and move on to something else.
In I my experience, the basis for having sustainable and maintainable systems have been well known and tested in Debian, and several other distributions, for over two decades.
At FOSDEM, we thought that we need a name for such a mindset.
Between beers, that name came to be "debops". (It's not just Debian, though: many other distributions get it right, too)
Oxford
2 public comments
Ineed nice writeup!. Very well reasoned. I being myself a Debian guy had been questioned multiple times why I want to package fonts/webapps by my friends. But as Enrico said I sympathize with my sysadmin friends who had keep system running without messing things up
India

“[Debian's release cycle] gives me a release rhythm that allows me to enjoy the sweet hum of spinning fans thinking about my next mischief, instead of spending my waking time chasing configuration file changes and API changes deep down in my dependency chain.”
Earth, Sol system, Western spiral arm

If you listen to Radio 4 from 0810 on BBC iPlayer, you’ll hear a debate between Phil Booth of MedConfidential and Tim Kelsey of NHS England – the guy driving the latest NHS data grab.
Tim Kelsey made a number of misleading claims. He claimed for example that in 25 years there had never been a single case of patient confidentiality compromise because of the HES data kept centrally on all hospital treatments. This was untrue. A GP practice manager, Helen Wilkinson, was stigmatised stignatised as an alcoholic on HES because of a coding error. She had to get her MP to call a debate in Parliament to get this fixed (and even after the minister promised it had been fixed, it hadn’t been; that took months more pushing).
Second, when Tim pressed Phil for a single case where data had been compromised, Phil said “Gordon Brown”. Kelsey’s rebuttal was “That was criminal hacking.” Again, this was untrue; Gordon Brown’s information was accessed by Andrew Jamieson, a doctor in Dunfermline, who abused his authorised access to the system. He was not prosecuted because this was not in the public interest. Yeah, right. And now Kelsey is going to give your GP records not just to almost everyone in the NHS but to university researchers (I have been offered access though I’m not even a medic and despite the fact that academics have lost millions of records in the past), to drug firms like GlaxoSmithKline, and even to Silicon-Valley informatics companies such as 23andme. 23andme.
Oxford
Checking if your servers are configured correctly can be done with IT automation tools like Puppet, Chef, Ansible or Salt. They allow an administrator to specify a target configuration and ensure it is applied. They can also run in a dry-run mode and report servers not matching the expected configuration.
On the other hand, serverspec is a tool to bring the well known RSpec, a testing tool for the Ruby programming language frequently used for test-driven development, to the infrastructure world. It can be used to remotely test server state through an SSH connection.
Why one would use such an additional tool? Many things are easier to express with a test than with a configuration change, like for example checking that a service is correctly installed by checking it is listening to some port.
Getting started
Good knowledge of Ruby may help but is not a prerequisite to the use of serverspec. Writing tests feels like writing what we expect in plain English. If you think you need to know more about Ruby, here are two short resources to get started:
serverspec’s homepage contains a short and concise tutorial on how to get started. Please, read it. As a first illustration, here is a test checking a service is correctly listening on port 80:
describe port(80) do it { should be_listening } end
The following test will spot servers still running with Debian Squeeze instead of Debian Wheezy:
describe command("lsb_release -d") do it { should return_stdout /wheezy/ } end
Conditional tests are also possible. For example, we want to check the
miimon parameter of bond0, but only when the interface is present:
has_bond0 = file('/sys/class/net/bond0').directory? # miimon should be set to something other than 0, otherwise, no checks # are performed. describe file("/sys/class/net/bond0/bonding/miimon"), :if => has_bond0 do it { should be_file } its(:content) { should_not eq "0\n" } end
serverspec comes with a
complete documentation of available resource types (like port
and command) that can be used after the keyword describe.
When a test is too complex to be expressed with simple expectations,
it can be specified with arbitrary commands. In the below example, we
check if memcached is configured to use almost all the available
system memory:
# We want memcached to use almost all memory. With a 2GB margin. describe "memcached" do it "should use almost all memory" do total = command("vmstat -s | head -1").stdout # ➊ total = /\d+/.match(total)[0].to_i total /= 1024 args = process("memcached").args # ➋ memcached = /-m (\d+)/.match(args)[1].to_i (total - memcached).should be > 0 (total - memcached).should be < 2000 end end
A bit more arcane, but still understandable: we combine arbitrary shell commands (in ➊) and use of other serverspec resource types (in ➋).
Advanced use
Out of the box, serverspec provides a strong fundation to build a compliance tool to be run on all systems. It comes with some useful advanced tips, like sharing tests among similar hosts or executing several tests in parallel.
I have setup a GitHub repository to be used as a template to get the following features:
- assign roles to servers and tests to roles;
- parallel execution;
- report generation & viewer.
Host classification
By default, serverspec-init generates a template where each host has
its own directory with its unique set of tests. serverspec only
handles test execution on remote hosts: the test execution flow (which
tests are executed on which servers) is delegated to some
Rakefile1. Instead of extracting the list of hosts to test
from a directory hiearchy, we can extract it from a file (or from an
LDAP server or from any source) and attach a set of roles to each of them:
hosts = File.foreach("hosts") .map { |line| line.strip } .map do |host| { :name => host.strip, :roles => roles(host.strip), } end
The roles() function should return a list of roles for a given
hostname. It could be something as simple as this:
def roles(host) roles = [ "all" ] case host when /^web-/ roles << "web" when /^memc-/ roles << "memcache" when /^lb-/ roles << "lb" when /^proxy-/ roles << "proxy" end roles end
In the snippet below, we create a task for each server as well as a
server:all task that will execute the tests for all hosts (in ➊). Pay
attention, in ➋, at how we attach the roles to each server.
namespace :server do desc "Run serverspec to all hosts" task :all => hosts.map { |h| h[:name] } # ➊ hosts.each do |host| desc "Run serverspec to host #{host[:name]}" ServerspecTask.new(host[:name].to_sym) do |t| t.target = host[:name] # ➋: Build the list of tests to execute from server roles t.pattern = './spec/{' + host[:roles].join(",") + '}/*_spec.rb' end end end
You can check the list of tasks created:
$ rake -T rake check:server:all # Run serverspec to all hosts rake check:server:web-10 # Run serverspec to host web-10 rake check:server:web-11 # Run serverspec to host web-11 rake check:server:web-12 # Run serverspec to host web-12
Parallel execution
By default, each task is executed when the previous one has
finished. With many hosts, this can take some time. rake provides
the -j flag to specify the number of tasks to be executed in
parallel and the -m flag to apply parallelism to all tasks:
$ rake -j 10 -m check:server:all
Reports
rspec is invoked for each host. Therefore, the output is something
like this:
$ rake spec env TARGET_HOST=web-10 /usr/bin/ruby -S rspec spec/web/apache2_spec.rb spec/all/debian_spec.rb ...... Finished in 0.99715 seconds 6 examples, 0 failures env TARGET_HOST=web-11 /usr/bin/ruby -S rspec spec/web/apache2_spec.rb spec/all/debian_spec.rb ...... Finished in 1.45411 seconds 6 examples, 0 failures
This does not scale well if you have dozens or hundreds of hosts to
test. Moreover, the output is mangled with parallel
execution. Fortunately, rspec comes with the ability to save results
in JSON format. Those per-host results can then be consolidated into a
single JSON file. All this can be done in the Rakefile:
-
For each task, set
rspec_optsto--format json --out ./reports/current/#{target}.json. This is done automatically by the subclassServerspecTaskwhich also handles passing the hostname in an environment variable and a more concise and colored output. -
Add a task to collect the generated JSON files into a single report. The test source code is also embedded in the report to make it self-sufficient. Moreover, this task is executed automatically by adding it as a dependency of the last serverspec-related task.
Have a look at the complete Rakefile for more details on
how this is done.
A very simple web-based viewer can handle those reports2. It shows the test results as a matrix with failed tests in red:

Clicking on any test will display the necessary information to troubleshoot errors, including the test short description, the complete test code, the expectation message and the backtrace:

I hope this additional layer will help making serverspec another feather in the “IT” cap, between an automation tool and a supervision tool.
-
A
Rakefileis aMakefilewhere tasks and their dependencies are described in plain Ruby.rakewill execute them in the appropriate order. ↩ -
The viewer is available in the GitHub repository in the
viewer/directory. ↩
Oxford
1 public comment
Spannend.
Berlin, Germany
Next Page of Stories